Návrh bezpečných databázových systémů
Daniel Cvrček
ÚIVT FEI VUT Brno
cvrcek@dcse.fee.vutbr.cz
Abstrakt
V této přednášce se budu věnovat logické databázové bezpečnosti. Logický
návrh a bezpečnostních pravidel zahrnuje jak bezpečný OS, tak i bezpečný
databázový systém a další bezpečnostní procedury.
Celá přednáška je rozdělena na dvě části. V první části bych stručně
zrekapituloval mechanismy, různé architektury bezpečných databází. Ve druhé
částí bude rozebrán celý proces návrhu databázového systému.
Obsah
1. Bezpečnostní požadavky
1.1 Tajemství
1.2 Integrita
2. Architektury bezpečných databázových systémů
2.1 Trusted Subject Architecture
2.2 The Woods Hole Architecture
2.2.1 Integrity
Lock Architecture
2.2.2 Kernelized
Architecture
2.2.3 Replicated
Architecture
2.2.4 Poznámky
3. Návrh bezpečného DBMS
3.1 Úvodní analýza (preliminary analysis)
3.2 Analýza požadavků a výběr politik
3.2.1 Kritéria
pro výběr politik
3.3 Konceptuální návrh
3.4 Logický návrh
3.5 Fyzický návrh
3.5.1 Implementace
bezpečnostních mechanismů
3.6 Verifikace a testování
4. Literatura
1. Bezpečnostní požadavky
Návrh databázového systému by měl brát bezpečnostní otázky v úvahu už od
počátku. Důvodem je cena, protože upravit existující systém na bezpečný
je řádově náročnější a dražší, než zakomponování bezpečnostních prvků již
ve fázi návrhu, kdy jsou tyto náklady velmi nízké.
1.1 Tajemství
Jestliže budeme na databázi požadovat zachování tajemství v ní uchovávaných
informací, pak bychom měli brát v úvahu následující požadavky:
-
Různé stupně granularity přístupu - DB musí být schopna zajistit
kontrolu přístupu na různých úrovních (např. u relačních DB - databáze,
kolekce relací, relace, sloupce relace, řádky relace, průnik sloupců a
řádku relace).
-
Různé typy přístupu - přístup musí být rozdělen podle dostupných
operací nad konkrétními typy dat (read, write, nebo select, insert, update,
delete).
-
Různé typy kontroly přístupu - kontrola přístupu může být
založena na různých vlastnostech dat. Např. na obsahu, kontextu (čas, místo),
historii (sekvence dotazů), výsledku kontrolní procedur, které se provádějí
v době dotazu.
-
Dynamické autorizace - DBMS by měl podporovat průběžné změny
oprávnění uživatelů v závislosti na úlohách, které právě provádějí.
-
Víceúrovňová ochrana - tento požadavek je determinován prostředím.
Jestliže je ovšem položen, tak musí být zajištěn pomocí povinného řízení
přístupu.
-
Skryté kanály - pokud možno by se v systému neměli vyskytovat
- neměla by existovat možnost získat neoprávněně data nepřímými metodami
komunikace.
-
Kontrola inference - tato kontrola se vztahuje hlavně na
agregaci a asociaci dat. Je nutno ošetřit větší citlivost agregovaných
dat oproti jednotlivým položkám a také zabránit zjištění citlivých informací
pomocí vztahů k neklasifikovaným datům.
-
Násobnost výskytu - jedna z možností zajištění kontroly inference.
Data se v databázi vyskytují několikrát, pokaždé s jinou bezpečnostní klasifikací.
-
Audit - všechny akce týkající se bezpečnosti by měli být
strukturovaně zaznamenávány (systémové žurnály, auditní záznamy a systémové
záznamy) a průběžně analyzovány
-
Kontrola toků - kontrola cíle výstupních dat, jež byly získány
oprávněným přístupem.
-
Zadní vrátka - musí být zajištěno, že žádný takovýto skrytý
přístup neexistuje.
-
Jednotnost mechanismů - pro zajištění různých bezpečnostních
politik a kontrol (tajemství, integrita) by měli být použity univerzální
mechanismy.
-
Rozumný výkon - systémové nároky pro zajištění bezpečnosti
v databázi by měl zůstat na co nejnižší úrovni, aby nebyl zbytečně snižován
výkon systému.
1.2 Integrita
Tak jako existují požadavky na zajištění tajemství informace, tak existují
i obecné principy pro zajištění integrity dat, které jsou nezávislé na
kontextu DBMS, nebo na charakteristice aplikací.
-
Dobře utvořené transakce - také jinak vázaná změna (constrained
change). Každá transakce musí mít následující vlastnosti: atomičnost chyb,
serializovatelnost, postup a korektní změnu stavu. Poslední bod, je v praxi
omezen pouze na doménové a entitní omezení.
-
Ověření uživatelé - změny v DB mohou být realizovány pouze
uživateli, jejichž totožnost byla ověřena.
-
Nejnižší oprávnění - v oblasti integrity se také nazývá need-to-do
(potřebuji k práci). Příklad: uživatel Smith může měnit platy zaměstnanců
v rozmezí 5-ti procent.
-
Oddělení rolí - stručně řečeno, jednotlivý uživatel by neměl
být schopen sám narušit integritu dat v databázi. Pro jakoukoliv změnu
je třeba souhlasu, nebo spolupráce několika jedinců.
-
Nepřetržitost operací - tedy problém zajištění činnosti systému
přitahuje velkou pozornost. Navržené postupy jsou založeny na replikaci
dat.
-
Rekonstrukce událostí - je založena na auditních záznamech,
kdy se kontroluje zneužití oprávnění konkrétními uživateli. Buď je možno
zaznamenávat kompletní historii jednotlivých datových položek, nebo identity
uživatelů pro každou změnu. V poslední době jsou navrhovány expertní systémy
pro analýzu vytvořených záznamů.
-
Kontroly skutečnosti - periodické kontroly konzistence dat
v databázi se skutečným stavem věcí. Je mimo působnost DBMS.
-
Snadnost bezpečného používání - nejjednodušší způsob práce
s DBMS by měl být nejbezpečnější. Tedy všechny bezpečnostní procedury jsou
jednoduché, uživatelsky přívětivé a bez chyb.
-
Delegace pravomocí - tato delegace by měla být snadná tak,
aby nebyl problém kopírovat bezpečnostní politiky. Je to základní schopnost
pro promítnutí hierarchie v organizaci.
2. Architektury bezpečných databázových systémů
Bezpečné databázové systémy mohou pracovat ve dvou různých režimech: system-high
a multilevel. V prvním případě mají všichni uživatelé maximální bezpečnostní
úroveň a odpovědná osoba musí kontrolovat nová data před tím, než budou
uvolněna do systému.
Pro druhou možnost existuje několik typů architektur, které jsou založeny
jak na důvěryhodných, tak i na nedůvěryhodných DBMS. Základní dvě architektury
jsou Trusted subject architecture a Woods Hole Architecture. Tu
druhou je možno rozdělit na Integrity Lock, Kernalized architectures
a Replicated architectures.
|
Typ architektury
|
Výzkumný prototyp
|
Komerční produkt
|
|
Integrity Lock
|
Mitre
|
TRUDATA
|
|
Kernelized
|
SeaView
|
Oracle
|
|
Replicated
|
NRL
|
|
|
Trusted Subject
|
A1 secure DBMS
|
Sybase, Informix, Ingres, Oracle, DEC, Rubix
|
2.1 Trusted Subject Architecture
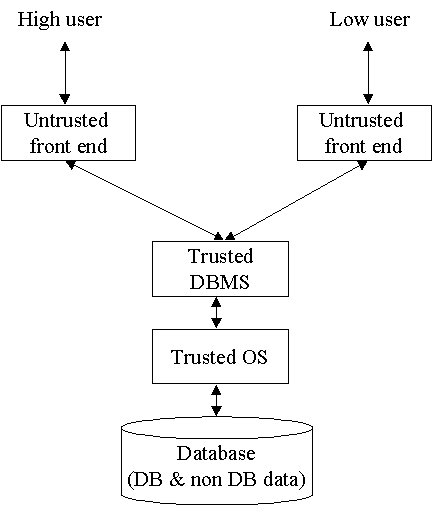
Nedůvěryhodná rozhraní jsou použita k připojení uživatelů na určité bezpečnostní
úrovni. Samotný DBMS už je důvěryhodný, tak jako i OS. Databázový a operační
systém jsou jedna entita a tvoří TCB.
2.2 The Woods Hole Architecture
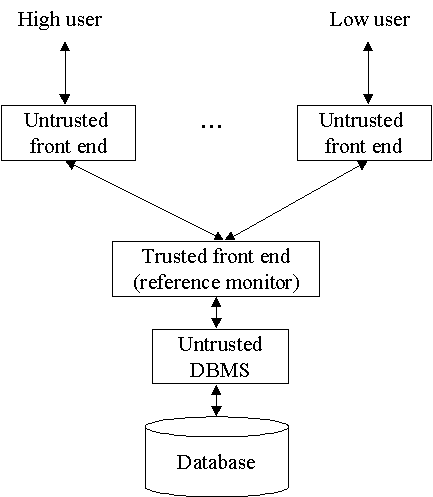
Tato architektura vznikla v roce 1982 a je rozdělena na tři už zmiňované
podtřídy. Obecné schéma je na obrázku.
Uživatele pracují s množinou nedůvěryhodných rozhraní pro různé bezpečnostní
úrovně. Ty komunikují s důvěryhodným rozhraním (front end), které funguje
jako referenční monitor. samotný databázový systém je opět nedůvěryhodný.
2.2.1 Integrity Lock Architecture
Nedůvěryhodná rozhraní jsou odpovědná za zpracování dotazu, optimalizaci
a projekce. Důvěryhodný filtr má za úkol vynucovat bezpečnostní funkce
a víceúrovňovou ochranu (ekvivalent TCB).
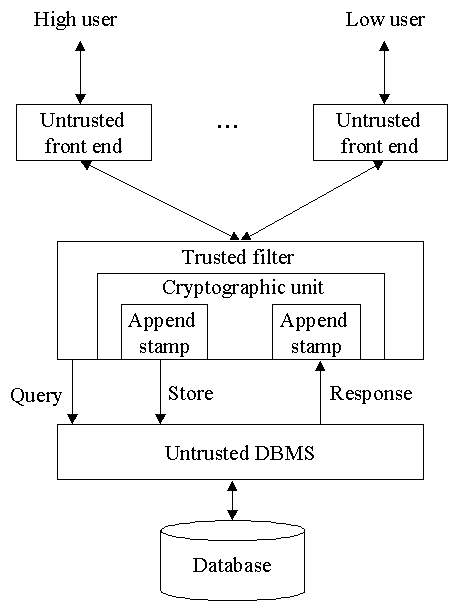
Víceúrovňovou ochranu zabezpečuje přidáváním bezpečnostních štítků
k objektům - stamps. Ty obsahují kontrolní data v zašifrované podobě
(mechanismu se říká Integrity Lock). Při přístupu k datům jsou tyto pečeti
zkontrolovány a na jejich základě se rozhodne o povolení přístupu. Při
tomto uspořádání se zabrání nebezpečí změny klasifikace Trojskými koňmi.
Systém ovšem není odolný proti inferenčním útokům a proti úniku informací
přes Trojské koně.
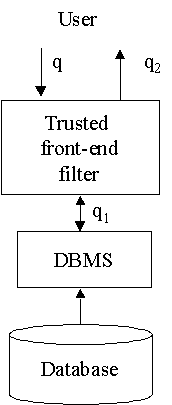
Aby bylo možno zabránit těmto nebezpečím, je nutné, aby všechny operace
nad daty (selekce, projekce, zpracování poddotazů, optimalizace a statistické
operace) byly v TFE, nebo v UFE, zatímco databáze je odpovědná pouze za
uložení a získání dat. Tak může TFE eliminovat data s vyšší klasifikací.
Denning navrhl úpravu, kdy mezi uživateli a DBMS je komunikační filtr,
který pokrývá inferenční rizika.
Původ tohoto řešení je ovšem v přístupu Maximal authorized view.
Každý dotaz je vyhodnocen podle pohledu, který obsahuje všechna data, která
uživatel může vidět. Tak je vytvořen qsec a je zabráněno inferenci.
Zadní filtr (back-end filter) je odpovědný za definici tohoto maximálního
pohledu (vyjmutí neoprávněných položek).
Tato architektura byla zahrnuta do produktů TRUDATA a do relačního databázového
stroje Sharebase.
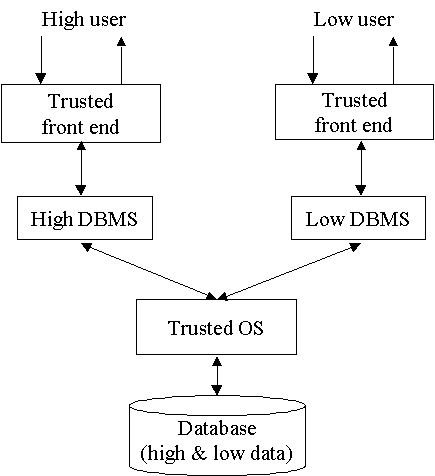
2.2.2 Kernelized Architecture
Je použit důvěryhodný operační systém, který je odpovědný za fyzický přístup
k databázi a za vynucení povinného řízení přístupu. Jak je vidět, tak uživatel
s vysokým oprávněním pracuje nad vysokou databází přes TFE a uživatelé
s nízkým oprávněním nad nízkou. Dotazy jsou poslány do OS, který získá
správná data z databáze. Data z databáze musí být rozděleny do OS objektů
podle bezpečnostní úrovně.
Je nutné implementovat dekompozici víceúrovňových relací a obnovu. Obnovou
se myslí opětné vytvoření víceúrovňových relací ze získaných jednoúrovňových.
Všechny operace jsou zaznamenávány na úrovni OS v auditním záznamu (vysoký
bezpečnostní stupeň).
Přístup je implementován v systému Oracle.
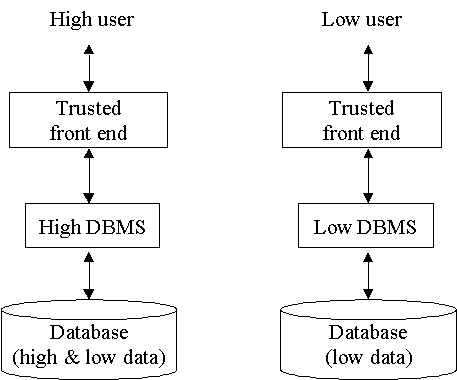
2.2.3 Replicated Architecture
V této metodě jsou použity dvě databáze. Jedna pro nízké objekty, druhá
pro nízké a vysoké objekty. Problémem je, kromě vysoké ceny, vytvoření
bezpečných synchronizačních algoritmů pro konzistentní replikaci dat. Cena
těchto algoritmů samozřejmě roste se zvětšováním svazu bezpečnostních úrovní.
2.2.4 Poznámky
Volba architektury závisí na prostředí. Kernelized architecture vyhovuje
tam, kde jsou jednoúrovňové tabulky, protože je nejlevnější a snadno implementovatelná.
Jestliže ovšem potřebujeme velkou pružnost bezpečnostních označení a vysoký
stupeň integrity mezi DBMS a OS, tak použijeme Integrity Lock architecture.
Architektura tructed subject je vhodná, jestliže jsme schopni zajistit
bezpečnou cestu mezi aplikacemi a DBMS.
Co se týká ohodnocení modelů, tak nejjednodušší je to u Integrity lock,
zatímco u Trusted subject musíme kontrolovat i funkce, jež jsou jinak součástí
bezpečného OS.
3. Návrh bezpečného DBMS
Bezpečnost databázového systému je buď prvořadým cílem, který je uvažován
už při návrhu systému, nebo je nutno upravit již existující systém tak,
aby vyhovoval nově vzniklým bezpečnostním požadavkům. Obvykle je uplatňován
druhý postup, kdy jsou k existujícímu systému přidávány bezpečnostní programové
balíky.
Vhodnou referencí pro klasifikaci bezpečných systémů, ale také šablonou
pro vývoj nových systémů je orange book, nebo evropský skoro ekvivalent
ITSEC. Tyto dokumenty je možno použít na zjištění všech klíčových požadavků,
které by měli být vzaty v úvahu.
Platným nástrojem při tvorbě databáze je několika stupňová metodologie,
která je v souladu s moderními principy návrhu programových systémů. Metodologie,
jež je navržena v rámci doporučení DoD má následující fáze:
-
Úvodní analýza
-
Bezpečnostní požadavky a politiky
-
Konceptuální návrh
-
Logický návrh
-
Fyzický návrh
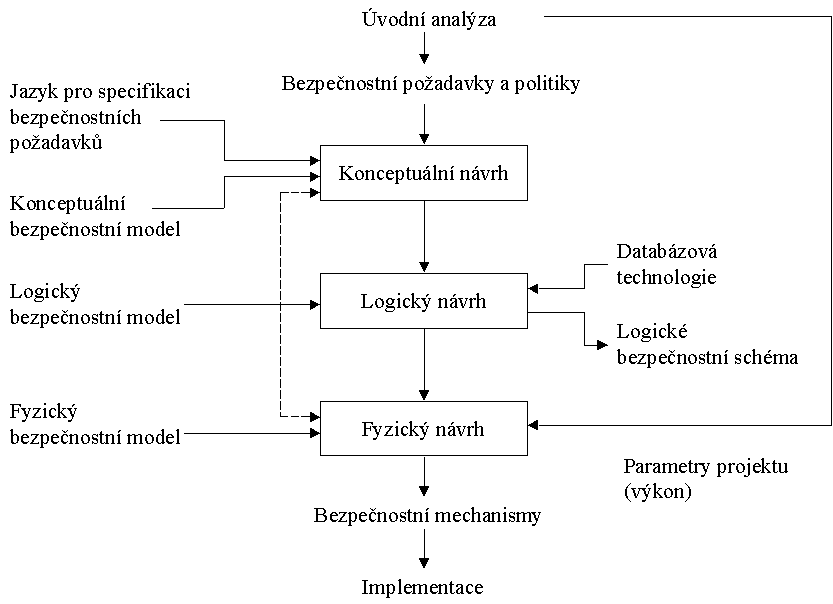
Tento postup umožňuje, aby bezpečnostní návrh byl včleněn do návrhu
databáze jako takové. Výhody takového přístupu jsou již dnes celkem známé.
Co se týká bezpečnosti tak nejdůležitější je oddělení mechanismů od politik,
což nám umožňuje:
-
definovat pravidla pro kontrolu přístupu a jejich hodnocení bez nutnosti
uvažovat implementaci
-
porovnat různé politiky pro kontrolu přístupu a různé mechanismy implementující
konkrétní politiky
-
navrhnout mechanismy, jež podporují různé politiky
-
dokazovat správnost bezpečnostního modelu s ohledem na požadavky
3.1 Úvodní analýza (preliminary analysis)
Úkolem je provést studii proveditelnosti pro bezpečnostní systém (po rozhodnutí
na strategické úrovni). Tato studie se skládá z ohodnocení rizik a z odhadu
ceny jak návrhu, tak samotného systému. Také jsou definovány aplikace,
jež je nutno vytvořit a jejich priorita. V úvahu je nutno brát:
-
systémová rizika - významné hrozby, jejich výskyt a následné
ztráty (analýza rizik)
-
vlastnosti databázového prostředí - ty určují hlavní linie
politik, které budou pro DB systém zvoleny
-
použitelnost existujících bezpečnostních produktů - kritériem
je výhodnost použití existujících produktů k vývoji vlastních
-
integrovatelnost bezpečnostních produktů - možnost integrace
bezpečnostních mechanismů pomocí skutečných mechanismů
-
výkon výsledného bezpečnostního systému
Výsledkem této fáze je: množina hrozeb, kterým bude systém vystaven podle
priority a dále vyhodnocení použitelnosti existujících mechanismů spolu
se specifikací těch mechanismů, jež je třeba vytvořit.
Jestliže analýza ceny a zisku je kladná, tak se pokračuje další fází.
3.2 Analýza požadavků a výběr politik
Prvním krokem je přesná studie všech možných hrozeb, kterým může být systém
vystaven. Požadavky na ochranu se mohou velmi lišit. Prvním měřítkem je
citlivost dat. Dále je možno rozdělit systémy na vysoce rizikové a nízko
rizikové v závislosti na úrovni korelace mezi daty, sdílení dat uživateli,
přístupnosti dat (kdo může přistupovat k jakým datům a za jakým účelem),
schopnostech a množství uživatelů a vybraných technologiích (certifikované
nebo dostatečně testované produkty kontra nedůvěryhodní tvůrci programů).
Během tohoto kroku by měl být určen stupeň zranitelnosti systému podle
útoků na prostředí budoucího nasazení systému. Systematický přístup se
skládá z kroků
-
analýza hodnoty - jsou analyzována data a aplikace, které
k nim budou přistupovat a na tomto základě je určena úroveň jejich citlivosti
-
identifikace hrozeb - identifikace možných hrozeb u různých
aplikací a možné metody průniku
-
analýza zranitelnosti - s ohledem na hrozby jsou nalezena
slabá místa systému
-
analýza rizik - možné hrozby, slabá místa systému a způsoby
průniku jsou postaveny proti možným porušením bezpečnosti systému a narušením
integrity dat
-
ohodnocení rizik - výsledky předchozí analýzy jsou ohodnoceny
pravděpodobností a schopností systému reagovat
-
definice požadavků - na základě ohodnocených hrozeb a pravděpodobnosti
jejich výskytu
Výsledkem je definice přístupových práv, tříd uživatelů s povolenými oprávněními
k databázi a bezpečností požadavky ve formě neformálních vět.
3.2.1 Kritéria pro výběr politik
-
bezpečnost kontra integrita kontra spolehlivost - určení
poměru důležitosti
-
maximální sdílení kontra minimální oprávnění - nalezení vhodné
hranice mezi extrémy
-
granularita kontroly - 1. na jaké množství entit je uplatňována
2. velikost rozeznávaných objektů
-
atributy použité pro kontrolu přístupu - základní: klasifikace
subjektu/objektu, místo, čas, stav systémových proměnných, historie přístupu
-
integrita - determinuje použití určitých modelů pro kontrolu
přístupu
-
priority - mezi pravidly jež specifikují politiky - specifičnost,
pravidlo zákazu
-
privilegia - implicitní privilegia, způsob jejich změny
-
pravomoc - úroveň 1 vlastní kontrola přístupu k objektům,
2 kontrola přístupu k informacím, jež jsou použity pro kontrolu přístupu,
3 informace definující, kdo může přistupovat k těm v 2
-
dědičnost - propagace přístupových práv na objekty jejich
potomkům
3.3 Konceptuální návrh
V této fázi jsou požadavky a politiky z předchozí části formalizovány.
Implementace ještě stále není uvažována. Konceptuální bezpečnostní model
je definován:
-
identifikací subjektů a objektů z bezpečnostního pohledu
-
identifikací přístupových práv pro různé subjekty s hledáním možných přístupových
omezení
-
analýzou propagace oprávnění v systému přes oprávnění grant/revoke
Model by měl reprezentovat sémantiku databázové bezpečnosti, měl by podporovat
analýzu toků oprávnění a také by měl být oporou pro administrátora při
tvorbě dotazů na aktuální stav oprávnění.
Základními vlastnostmi konceptuálního modelu jsou kompletnost a konzistence
a neredundance. V této fázi je možné ověřovat vlastnosti bezpečnostního
systému.
Jelikož je tento krok velmi obtížný, je nutné vždy na závěr provést
jak validaci, tak verifikaci.
3.4 Logický návrh
Konceptuální bezpečnostní model je transformován do logického modelu, jež
je použit v daném databázovém systému. Navíc je nutno brát ohled na mechanismy
OS. Účelem je identifikovat bezpečnostní požadavky, jež mohou zajistit
existující prostředky. Závěrem této části návrhu je určení, které požadavky
může plnit OS, které DBMS a pro které je nutno vytvořit nové mechanismy.
3.5 Fyzický návrh
V této fázi jsou rozpracovány detaily ohledně organizace paměti, vlastní
implementace, případně integrace požadovaných mechanismů. Fyzická struktura
přístupových pravidel, jejich vztah k fyzickým strukturám databáze.
Zpětná vazba při problémech je na konceptuální a logický návrh.
3.5.1 Implementace bezpečnostních mechanismů
Tady se zmíním jen o základních pravidlech pro vytváření nových bezpečnostních
mechanismů.
-
ekonomie mechanismů - co nejvyšší jednoduchost
-
efektivnost - nároky na strojový čas
-
linearita nákladů - náklady po instalaci jsou úměrné používání
-
oddělení oprávnění - pokud je to možné tak vrstvit několik
různých mechanismů s různým přístupem
-
minimální oprávnění - i programy by měli požadovat minimální
potřebná oprávnění (izolace dopadů chyb, údržba, obrana před trojskými
koňmi, demonstrace správnosti)
-
úplné zprostředkování - každý přístup k objektu musí projít
přes mechanismus
-
známý návrh - u převzatých mechanismů
-
implicitní bezpečnost - pokud uživatel nezvolí jinak, tak
je preferována bezpečnost
-
minimum podpůrných mechanismů - ty, jež jsou potřebné pro
činnost dalších mechanismů
-
psychologická přijatelnost - jednoduchost a snadnost užívání
-
pružnost - podpora různých politik, filozofie nepřátelského
prostředí
-
izolace - od ostatních částí systému
-
verifikovatelnost - s ohledem na požadavky politiky
-
kompletnost a konzistence
-
kontrolovatelnost - jak činnost, tak i útoky na mechanismus
je možno sledovat
-
problém reziduí - zbytky dat po činnosti procesu na disku
či v paměti
-
neviditelnost dat - neoprávnění uživatelé se nedozvědí ani
strukturu dat
-
faktor námahy - obejití mechanismu je co možná nejnákladnější
-
úmyslné pasti - snadné na odhalení pro zlomyslné uživatele,
slouží ke sledování pokusů o průnik do systému
-
nouzová opatření - v případě nouze by měl existovat způsob,
jak mechanismus dočasně vyřadit
-
programovací jazyk - důvěryhodnost použitého překladače
-
správnost - model musí být mechanismy interpretován přesně.
3.6 Verifikace a testování
Cílem této poslední fáze je ověření správnosti implementace zvolených bezpečnostních
požadavků a politik. Metody pro tento účel můžeme rozdělit na formální
a neformální.
Neformální:
-
křížová kontrola požadavky/zdrojové texty, nebo požadavky/chování za běhu
-
revize programového kódu, detekce chyb a nekonzistencí
-
analýza chování programu podle různých parametrů a testování různých cest
provádění
-
testování, krokování
Jejich výhodou je rychlá aplikovatelnost, ale není možno provést kontrolu
chování programu ve všech situacích.
Formální metody jsou dokonalejší, díky základnímu matematickému modelu.
Příkladem může být dokazování bezpečnostních axiomů pro ověření formálního
modelu požadavků. Nejabstraktnější formální specifikace jsou zjemňovány
až do specifikací na úrovni vývoje programu. Verifikace pak probíhá odzdola
nahoru.
4. Literatura
[1] Castalo S., Fugini M. G., Martella G., Samarati P.: Database security.
Addison-Wesley & ACM Press, 1995