Základy
Dalsí dovednosti
Tip: Vsechny zdejsí stránky muzete vytisknout z vaseho prohlízece bezným zpusobem. Jejich formátování se automaticky upraví pro potreby tisku.


Profiler je program, který umí statisticky analyzovat, ve kterých funkcích a cyklech program tráví nejvíce casu. Jen takto vytipované cásti kódu pak má smysl optimalizovat. Je zbytecné ztrácet cas optimalizováním funkce, která se pri behu programu vyvolá jednou a program v ní stráví pár milisekund.
Profilování se obvykle skládá se dvou kroku. První krok muzeme nazvat merením. Jde o získávání statistických údaju o bezícím programu. Tyto údaje se obvykle ukládají do nejakého pomocného logovacího souboru. Zaznamenávají se do nej zejména pocty vyvolání jednotlivých funkcí, pocty iterací v jednotlivých cyklech, pocty prístupu do pameti (cache, RAM), prípadne i pocty prístupu na disk nebo k jiným zdrojum (sít, ruzná zarízení, atd.). Dále se zaznamenává i doba strávená pri techto zaznamenaných cinnostech.
Druhý krok profilování lze nazvat profilovací analýza. V tomto kroku získáváme z namerených údaju ruzné statistiky. Existují programy s grafickým rozhraním, které umoznují nejenom spocítat, která funkce byla volána nejcasteji, ale dokází se na namerená data podívat z ruzných úhlu a zobrazit výsledky prehledne pomocí tabulek nebo grafu. Pomocí profilovací analýzy se obvykle snazíme vytipovat ta místa programu, v nichz program tráví nejvíce casu. Tím, ze získáme prehled o tom, jak se jednotlivé funkce podílejí na celkové dobe behu programu nebo na prístupu k jiným zdrojum (pamet, sít, atd.), se muzeme lépe rozhodnout která místa a jakým zpusobem budeme optimalizovat.
Vysvetlili jsme si, ze profilování se skládá ze dvou kroku, merení a analýzy. Tomu odpovídá i rozdelení nástroju pro profilování. Jedna cást nástroju se zameruje na sbírání údaju o behu programu, dalsí programy se pak zamerují na analýzu a prezentaci namerených dat.
Generování údaju o behu programu úzce souvisí s instrumentací programu. Jednoduchou analýzu muzeme provádet sami tím, ze do svého kódu doplníme vhodné výpisy, pomocí nichz poté spocítáme, kolikrát program navstívil sledovaná místa v programu. Vhodné je umístit výpisy na zacátky a konce vsech funkcí a také vsech cyklu, protoze to jsou místa, kde program typicky tráví nejvíce casu. Nevýhodou tohoto prístupu je pracnost a nespolehlivost. Snadno muzeme na nekteré významné místo zapomenout. Dalsí nevýhodou muze být i fakt, ze takto doplnená instrumentace ciní zdrojový kód méne prehledným.
Dalsí mozností je generování dat pro profilovací analýzu automatizovaným zpusobem budto samotným prekladacem nebo specializovaným programem. Princip sberu dat zustává podobný jako pri rucní instrumentaci zdrojového kódu. Rozdíl je ale v tom, ze nyní zustává zdrojový kód nedotcený.
Principiálne podobný zpusob sberu dat jako rucní doplnování kódu o pomocné výpisy nabízejí samotné prekladace. Pokud se budeme zabývat programováním v jazycích C a C++ a pouzijeme prekladac GCC, muzeme snadno získávat profilovací data tak, ze program prelozíme s prepínacem -p, resp. -pg. Prekladac pak prímo do výsledné aplikace doplní kód, který po spustení programu generuje tzv. graf volání (call graph) a ulozí jej do souboru gmon.out. Pomocí programu prof, resp. gprof se pak zobrazí výsledky analýzy v citelné forme.
$ gcc -prepinace -pg program.c -o program $ ./program -parametry $ gprof ./program
Vsimnete si, ze program gprof má jako parametr sledovaný binární program. Jedna ze zobrazených tabulek pak muze vypadat takto:
% cumulative self self total time seconds seconds calls ms/call ms/call name 0.00 0.00 0.00 243 0.00 0.00 isBadNumber 0.00 0.00 0.00 81 0.00 0.00 bToC 0.00 0.00 0.00 81 0.00 0.00 bToR 0.00 0.00 0.00 9 0.00 0.00 isBlockSolved 0.00 0.00 0.00 9 0.00 0.00 isColSolved 0.00 0.00 0.00 9 0.00 0.00 isRowSolved 0.00 0.00 0.00 1 0.00 0.00 _readMatrix 0.00 0.00 0.00 1 0.00 0.00 allocMatrix
Význam jednotlivých sloupcu je následující.
Tento prístup k profilování má své výhody i nevýhody. Výhodou je, ze zdrojový kód programu zustává nedotcený a vse za nás udelá prekladac. Nevýhoda tohoto prístupu se projeví u aplikací, které jsou slozeny z více knihoven, kdy nekteré cásti aplikace jsou prelozeny s prepínacem pro generování profilovacích informací a nekteré ne.
Posledním prístupem, který si zde ukázeme je pouzití programu Callgrind a KCachegrind. Callgrind je modul programu valgrind. Jeho prístup k získávání profilovacích informací je odlisný od predchozích prístupu. Valgrind funguje jako interpret programu, který sleduje, co program delá.
$ valgrind --tool=callgrind ./program -parametry
Zaznamenávaná data se standardne ukládají do souboru callgrind.out.pid, kde pid je císlo procesu. Tímto zpusobem lze generovat profilovací údaje pro ruzné kombinace spoustecích parametru a vzájemne je porovnávat. Výsledný soubor lze prohlédnout a analyzovat napríklad programem KCachegrind.
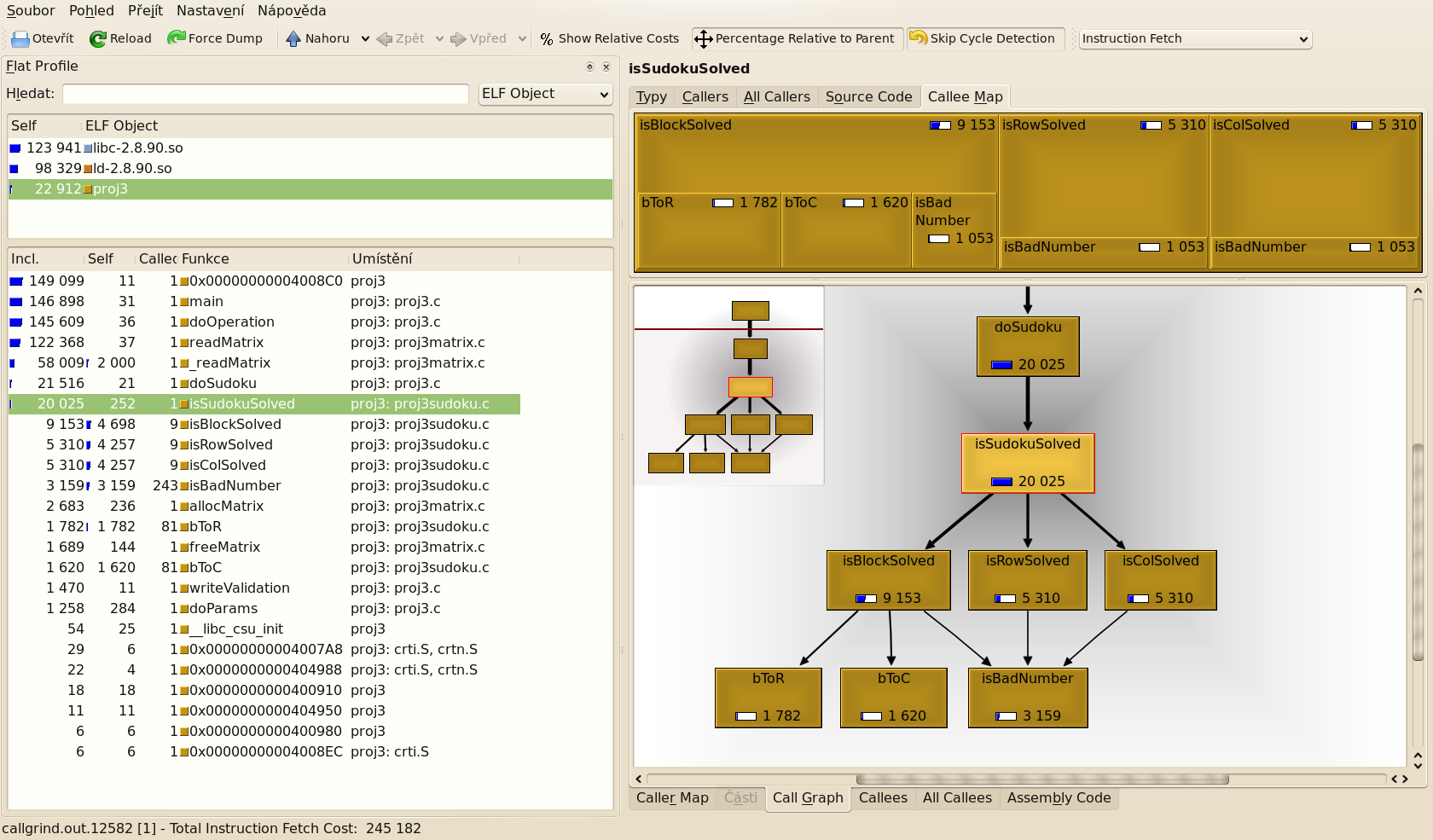
Základní údaje, které KCachegrind zobrazuje v pohledu Flat profile jsou tyto:
Pomocí dalsích pohledu lze zobrazit ruzné dalsí zajímavé informace. Na obrázku je napríklad zobrazen graf volání a mapa volaných funkcí, které zobrazují cenu výpoctu názorneji nez tabulka.
Vedlejsím efektem získávání profilovacích údaju simulacním zpusobem je urcité zpomalení vykonávaného programu (cca 5x, profilovací kód generovaný prekladacem sice také zpomaluje, ale zrejme výrazne méne), ale poskytuje to zajímavejsí informace nez výse zminované prístupy. Výhodou callgrindu na druhou stranu je, ze lze analyzovat prakticky hotové programy, vcetne modulu a knihoven tretích stran, na jejichz preklad nemáme nejmensí vliv.
Predcasná optimalizace muze zpusobit více skody nez uzitku. Kdyz zacnete optimalizovat uz v prubehu vytvárení programu, kdyz jeste nemáte ujasneno, jak bude program nakonec vypadat, muze se vzápetí ukázat, ze jde o zbytecné úsilí. Navíc prílisné optimalizace na úrovni zdrojového kódu dost casto zatemnují podstatu reseného problému. Zvláste nepríjemné to muze být pri práci v týmu.
Analýza problému muze být uzitecnejsí nez optimalizace. Výsledky optimalizace resení s kvadratickou casovou slozitostí budou i po velkém úsilí vetsinou horsí nez neoptimalizované resení se slozitostí lineární. Znalosti matematiky a teorie jsou v dusledku lepsí nez znalosti nejruznejsích exotických konstrukcí programovacího jazyka.
Norma jazyka ISO C99 zavádí moznost pouzití statických inline funkcí. Pouzití klícových slov static inline pred hlavickou funkce (blizsí informace viz dokumentace GCC) nemá zádný vliv na výsledné chování programu, ale prekladac potom muze takto oznacené funkce prelozit bez kódu pro volání funkcí. Výsledek je pak podobný, jako kdyz se pouzije makro, ale s výhodou vetsí prehlednosti zdrojového kódu.
static inline int bToC(int b, int i, int order)
{
return order * (b%order) + (i%order);
}
Tímto zpusobem nelze osetrit vsechny funkce. Hodí se to pro velmi jednoduché funkce. Kdyz potom pri prekladu zapneme optimalizace, dojde ke zrychlení programu, protoze se usetrí kód nutný pro zavolání funkce (alokace pameti na zásobníku, skok). Pokud jde o funkci, která je volána opravdu casto, muze být úspora významná. Nezapomínejte ovsem na predchozí rady.
Oznacení funkce jako inline je pro prekladac jenom doporucení. Prekladac se pokusí vytvorit efektivnejsí kód, az kdyz zapneme generování optimalizovaného kódu pomocí prepínace. I kdyz jsou optimalizace zapnuté, muze prekladac vyhodnotit, ze funkci nelze prelozit efektivneji.
Pro úcely zkoumání programu pomocí profileru muze být uzitecné, kdyz program prelozíme zároven s prepínacem pro optimalizaci a pro generování ladících informací. Napríklad program KCachegrind potom dokáze zobrazovat cásti zdrojového kódu vcetne hodnocení ceny jednotlivých rádku programu.
Autor: David Martinek. Poslední modifikace: 9. October 2011. Pokud v tomto dokumentu narazíte na chybu, dejte mi prosím vedet.