| Vytváření IFS kódu |
| Předchozí kapitola | |||||||
| Obsah | |||||||
| Další kapitola |
Při vytváření IFS kódu i pro generování výsledné IFS koláže se používají afinní transformace. Afinní transformace vzniká složením několika lineárních transformací. Afinní transformace lze popsat různě, nejvýhodnější je však popis pomocí matic. Dosahuje se tak výrazného ušetření paměťového místa a současně i zrychlení výpočtu. Proto je potřeba zavést základní pojmy z lineární algebry a z maticového počtu, abychom pochopili další kapitoly.
Množina L libovolných prvků (budeme jim říkat vektory) se nazývá lineární prostor, jestliže:
Množina všech uspořádaných n-tic reálných čísel, na které jsou definovány operace sčítání a násobení reálným číslem, se nazývá aritmetický lineární prostor. Jeho prvky se nazývají aritmetické vektory.
| (1.1) |
Toto je matice typu n x n (n je pevně dané přirozené číslo). Matice budeme značit velkými písmeny.
Vektory z aritmetického lineárního prostoru Vn [^a]1* = (a11,a12 ... a1n) se nazývají řádkové vektory nebo řádky matice A.
Vektory z aritmetického lineárního prostoru Vn [^a]*1 = (a11,a21 ...an1) se nazývají sloupcové vektory nebo sloupce matice A.
Sčítání matic: nechť A a B jsou matice typu m x n. Součet matic A+B je matice X, která vznikne součtem daných prvků matice (součtem prvků na stejném místě v matici):
| (1.2) |
Sčítání je definováno pouze pro matice stejného typu.
Součin matic: Nechť A je matice typu m x n, B je matice typu n x p. Součin matic A a B je matice typu m x p pro jejíž prvky platí:
| (1.3) |
Hodnota na pozici i, j ve výsledné matici A.B tedy odpovídá skalárnímu součinu aritmetických vektorů pro i-tý řádek matice A a pro j-tý sloupec matice B. Součin matic A a B je definován pouze v případě, že počet sloupců matice A je roven počtu řádků matice B.
Je důležité si uvědomit, že pro matice platí:
A+B = B+A,
ale nemusí vždy platit:
A*B = B*A.
Nechť C je čtvercová matice řádu n. Zobrazení aritmetického lineárního prostoru Vn Ž Vn definované předpisem:
| (1.4) |
se nazývá lineární transformace ve Vn. Matice C se nazývá matice transformace.
Afinní transformace je definována vztahem:
| (1.5) |
Jedná se o maticový zápis, tedy:
| (1.6) |
Jednotlivé koeficienty matice A se uplatňují při rotaci, zkosení a změně měřítka, koeficienty matice B při posunutí.
Objekty, které budeme chtít zobrazit pomocí metody IFS, budeme reprezentovat obrysově. Existují i jiné možnosti reprezentace, například reprezentace plošná, ale u ní je transformační matice rozšířena o změnu barvy a kontrastu. Obrysová reprezentace má tu výhodu, že je jednoduchá jak pro zadávání dat uživatelem, tak i pro uložení dat v paměti počítače.
Práce při návrhu IFS spočívá v tom, že uživatel navrhne základní objekt, což není nic jiného než uspořádaný seznam vrcholů pospojovaných úsečkami. Zde se na uživatele nekladou žádné meze, je možné například vytvořit objekt, který má některé hrany protnuté. Na výsledný IFS nemá tvar základního objektu žádný vliv.
Další činnost, kterou musí uživatel vykonat, je pokrytí nakresleného základního objektu. To se děje tak, že uživatel na základní objekt pokládá objekty vzniklé ze základního objektu lineárními transformacemi. Uživatel tedy vytvoří kopii základního objektu, tu podrobí některé transformaci (nebo i více transformacím) a výsledný objekt potom položí na objekt základní.
Záleží jen na uživateli jak dokonale pokryje základní objekt. Při dokonalém pokrytí (to znamená, že se transformované objekty budou dotýkat přesně hranami a nebudou se překrývat) bude výsledná IFS koláž přesnou kopií základního objektu. Určité nepřesnosti jsou způsobeny matematickou chybou (vzhledem k iteračnímu procesu se chyby kumulují) a nedostatečným počtem iterací.
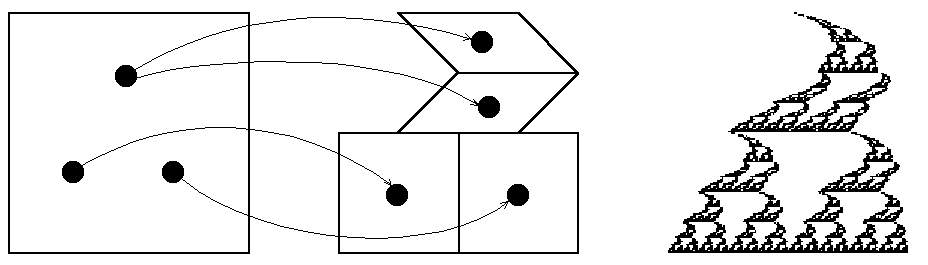
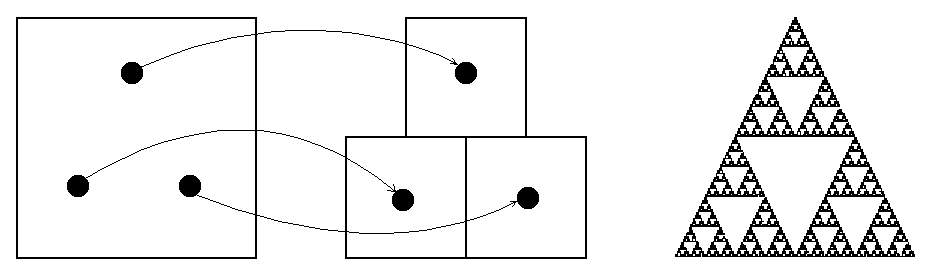
Při neúplném pokrytí vznikají ve výsledné IFS koláži prázdná místa, což může v některých případech vytvořit zajímavý motiv. Jestliže se naopak transformované objekty překrývají, má to za následek pomalejší vykreslování IFS koláže v důsledku toho, že jsou některé části koláže neustále překreslovány.
Jestliže uživatel vytvoří transformovaný objekt, jehož transformace není kontrakcí, je na to před vykreslením IFS koláže upozorněn. Program může vygenerovat i obrázek s takovouto transformací. V tomto případě ale již nejde o IFS, protože IFS je definován jako systém, ve kterém jsou funkce mající atraktor. Funkce, která není kontrakcí, nemá atraktor (ve skutečnosti je atraktorem nekonečno, myšleno ve smyslu dvou dimenzí). Problémem zde může být, že při generování IFS s nekontrahující transformací může nastat aritmetická chyba v důsledku přetečení výsledku transformace. V případě regulárních IFS (když jsou všechny transformace kontrahující) tento problém samozřejmě nenastává.
Celá práce uživatele při vytváření IFS tedy spočívá v nakreslení základního objektu a v jeho pokrytí. Tomu odpovídá i datová reprezentace v programu. První datovou strukturou je seznam vrcholů základního objektu, druhou datovou strukturou je seznam jednotlivých transformací.
Některé programy na vytváření IFS místo seznamu transformací udržují v paměti seznam vrcholů všech objektů, tedy objektu základního i objektů transformovaných. To má výhodu v rychlejším vykreslování vlastních objektů v editoru. Nevýhodou je nutnost výpočtu transformačních matic při generování IFS. Diskutabilní je paměťová náročnost. První metoda je příznivější v případě, že základní objekt má více než šest vrcholů, v opačném případě je lepší metoda druhá.
Jak již bylo řečeno, vzorec pro lineární transformaci má tvar:
| (1.7) |
kde xn, yn jsou souřadnice iterovaného bodu. Chceme tedy nalézt koeficienty aij a bi.
Na základní objekt lze aplikovat tyto lineární transformace:
Každá transformace je reprezentována maticí transformace. Matice transformace je matice řádu 3x3 a vzniká vlastně složením matic A a B. Výsledná transformace je vypočtena jako maticový součin jednotlivých základních transformací. Zde je nutno připomenout, že násobení matic není komutativní, což se mimo jiné projevuje tím, že prohozením pořadí dvou transformací vznikne odlišná výsledná transformace.
Pro výpočty s afinními transformacemi je někdy výhodné sloučit transformační matici A a translační matici B. Vznikne tak matice řádu 3x3. Také se přehodí pořadí pro násobení matice A s vektorem.
Novou transformační matici budeme nazývat Mx a vzorec pro afinní transformaci nabude tvaru:
| (1.8) |
Maticový zápis:
| (1.9) |
V dalším textu budeme všechny transformace zapisovat pouze pomocí této matice Mx.
Maticový zápis můžeme rozepsat na vztahy, které platí pro jednotlivé souřadnice transformovaného bodu:
| |||||||||||||||||||||
Poslední vztah není nutno uvádět, protože se v něm vyskytují pouze konstanty. Tento vztah by byl využit buď při aplikaci nelineární transformace, nebo při aplikaci perspektivního zobrazení.
| |||||||||||||||
Transformační matice:
| (1.15) |
| |||||||||||||||
Transformační matice:
| (1.18) |
| |||||||||||||||
Transformační matice:
| (1.21) |
| |||||||||||||||
Transformační matice:
| (1.24) |
| |||||||||||||||
Transformační matice:
| (1.27) |
| |||||||||||||||
Transformační matice:
| (1.30) |
| |||||||||||||||||
Transformační matice:
| (1.34) |
Tyto transformace vzniknou složením základních transformací. Operace se provede maticovým vynásobením matic jednotlivých transformací. Zde uvedené transformace jsou potřebné pro praktickou aplikaci základních transformací, neboť umožňují interaktivní zadávání transformací.
Jako příklad uveďme rotaci okolo zadaného bodu. Tato transformace je složená a má větší praktický význam, než základní transformace rotace okolo počátku, neboť ji lze aplikovat na libovolnou množinu bodů v ploše.
U složených transformací uvedeme pouze transformační matici, protože vzorce pro jednotlivé body lze jednoduše odvodit přímo z této matice.
| (1.35) |
| (1.36) |
| (1.37) |
| (1.38) |
| (1.39) |
| (1.40) |
Pokud máme aplikovat nějakou transformaci na již existující transformační matici, musíme provést maticový součin mezi starou transformační maticí a maticí reprezentující danou transformaci. Nebudeme zde uvádět všechny možnosti, které mohou nastat, ale předvedeme pouze princip. Půjde o provedení transformace změny měřítka na starou transformační matici.
V dalších vzorcích bude A stará transformační matice, Aó nová transformační matice a Mscale matice reprezentující změnu měřítka.
Změna měřítka o koeficient Ms:
| (1.41) |
| (1.42) |
Jestliže už známe všechny transformace, které budou vytvářet IFS fraktál, zbývá nám ještě dopočítat k zadaným transformacím jim odpovídající pravděpodobnosti, s jakou budou tyto transformace použity při generování. Bylo by samozřejmě možné, aby všechny transformace měly stejnou pravděpodobnost, to by ale nebylo výhodné z hlediska generování fraktálu. Transformace, které jsou hodně kontrahující, to znamená, že mají nízké koeficienty v transformační matici, by iterované body příliš přitahovaly k atraktoru. Výsledkem by byl málo rozvinutý fraktál, pro jehož generování by bylo nutno použít příliš vysoký počet iterací.
Proto je vhodné, aby byla jednotlivým transformacím přiřazena určitá pravděpodobnost, s jakou tyto transformace nastanou, přičemž hodně kontrahující transformace budou mít menší pravděpodobnost než transformace kontrahující méně. Při výpočtu pravděpodobností musíme dbát na to, aby součet všech pravděpodobností byl roven jedné.
V tomto programu je použito 7 možností, jak vypočítat pravděpodobnosti jednotlivých transformací:
Tato volba je používána ve všech programech, které umožňují modelovat a generovat IFS koláže. Pro běžné typy transformací dává dobré výsledky, to znamená, že rozložení pravděpodobností generované tímto vztahem, přibližně odpovídá ideálnímu rozložení.
Výhodou této metody je její jednoduchost, nevýhodou to, že některé pravděpodobnosti mohou vyjít nulové. To by znamenalo, že by se daná transformace nepodílela na generování fraktálu. Po aplikaci této metody tedy musíme ošetřit nulové pravděpodobnosti a přiřadit jim nějakou minimální nenulovou hodnotu.
Vyjdeme z transformační matice M, ze které spočítáme koeficient kontrakce podle vztahu:
| (1.43) |
Pravděpodobnost dané transformace i potom vypočteme jednoduše:
| (1.44) |
Tato volba spočítá plochu základního objektu tak, jak ho zadal uživatel. Potom se na vrcholy základního objektu aplikuje daná transformace a pro nově vygenerované body se spočítá plocha nového objektu. Pravděpodobnost dané transformace se spočítá pomocí obsahů těchto dvou obrazců:
| (1.45) |
Jde o nejpřesnější metodu pro výpočet pravděpodobností. Její nevýhodou je velká složitost z čehož plyne i časová náročnost. Také způsob výpočtu ploch obrazce nemusí vždy dát správné výsledky. To se stane v případě, kdy uživatel zadal určitým způsobem zdeformovaný tvar základního objektu, který má například dvě shodné hrany.
Výpočet obsahu objektu, který je zadaný seznamem svých vrcholů, z nichž každý vrchol má souřadnice [xn,yn], se provede pomocí algebraického součtu determinantů. Každý determinant je tvořen čtveřicí čísel, které jsou dány polohou dvou sousedních vrcholů na hranici objektu. Výsledná plocha je potom rovna polovině tohoto součtu:
| (1.46) |
| (1.47) |
Poslední determinant v řadě uzavírá celou posloupnost:
| (1.48) |
Nejprve se vypočítají minimální a maximální souřadnice základního objektu:
| |||||||||||||||||||||||||||||
Z těchto souřadnic se získá plocha obdélníka, který je opsaný základnímu objektu:
| (1.54) |
Poté se pro každý vrchol základního objektu provede transformace a spočtou se nové minimální a maximální souřadnice pro transformovaný základní objekt:
| |||||||||||||||||||||||||||||
Vypočteme plochu obdélníku, který je opsaný transformovanému objektu:
| (1.60) |
Výsledná pravděpodobnost dané transformace je dána vztahem:
| (1.61) |
Mohlo by se zdát, že by stačilo vypočítat ohraničující obdélník základního objektu a souřadnice vrcholů nového obdélníku získat transformací. Takový postup by nedával správný výsledek, neboť určité transformace by tento obdélník změnily na jiný tvar a vypočtený obsah by byl odlišný.
Tato metoda není tak přesná jako metoda předchozí. Její výhodou je jednoduchá implementace a jednoznačnost výsledků.
Tato metoda se podobá metodě předchozí. Základní rozdíl je v tom, že se neprovádí obalení základního objektu obdélníkem ale kružnicí. Pro výpočet pravděpodobnosti se potom porovnají obsahy obalujících kružnic základního objektu a objektu transformovaného.
Střed obalující kružnice se vypočítá jako aritmetický průměr souřadnic vrcholů základního objektu:
| |||||||||||||||||||||||
Pro výpočet obsahu obalující kružnice potřebujeme znát i její poloměr. Poloměr se vypočte jako maximální vzdálenost středu obalující kružnice a souřadnic vrcholů základního objektu:
| (1.64) |
kde xi a yi jsou souřadnice i-tého vrcholu základního objektu.
Obsah obalující kružnice se nyní vypočte snadno:
| (1.65) |
V druhém kroku nejprve provedeme transformaci všech vrcholů základního objektu. Dále zjistíme souřadnice středu nové kružnice:
| |||||||||||||||||||||||
Potom vypočteme poloměr kružnice, která obaluje tento nový objekt:
| (1.68) |
kde xió a yió jsou souřadnice i-tého vrcholu transformovaného objektu.
Obsah nové obalující kružnice:
| (1.69) |
Výsledná pravděpodobnost dané transformace je dána:
| (1.70) |
Tato metoda má stejné vlastnosti jako metoda předchozí. Výsledky se samozřejmě mohou lišit, neboť jde o odlišný způsob výpočtu. Výhodou je, že se počítají správně i ty transformace, u kterých dochází ke značnému zmenšení jedné souřadnice (například horizontální změna měřítka s malým faktorem zvětšení). U předchozí metody by obsah obdélníku byl blízký nule, ale v této metodě se díky způsobu výpočtu poloměru dosáhne uspokojivých výsledků.
Tato metoda využívá pro výpočet pravděpodobnosti koeficient zkrácení úsečky. Pro zjednodušení výpočtů neuvažujeme libovolnou úsečku. Výpočet se provede pro úsečku, která vychází z bodu [0,0] do bodu [1,1]. V tomto případě lze vzorec pro výpočet pravděpodobnosti i-té transformace přímo odvodit.
Zadané hodnoty:
| |||||||||||||||||||||||||||
Hodnoty vypočtené po aplikaci transformace:
| |||||||||||||||||||||||||||
Do těchto vztahů dosadíme hodnoty x0,x1,y0 a y1:
| |||||||||||||||||||||||||||
Délka netransformované úsečky je rovna:
| |||||||||||||||||||||
Délka transformované úsečky se vypočítá pomocí transformovaných bodů:
| ||||||||||||||||||||||||||||||||||||||||||||||||
Pravděpodobnost dané transformace se vypočte jako podíl těchto dvou délek:
| |||||||||||||||||||||||||||||||||||
Tato metoda je jednoduchá pro výpočet, ale má některé nevýhody. První nevýhodou je, že úsečka je jednorozměrná. To znamená, že pravděpodobnost je přímo úměrná změně délce úsečky. Přesnější výsledky dávají metody, které pravděpodobnost počítají jako změnu obsahu nějakého útvaru. Rozdíl je tedy v lineárním či kvadratickém poměru. Například transformace, která provede zmenšení objektu na polovinu bude mít pravděpodobnost rovnu 1/2. Budeme-li však pravděpodobnost počítat některou z předchozích metod, vyjde tato pravděpodobnost rovna 1/4. Tato hodnota je přesnější, neboť základní objekt pokryjeme čtyřmi objekty, z nichž každý je zmenšený na polovinu.
Druhou nevýhodou této metody je, že počítá zkrácení jen jedné pevně dané úsečky. To může způsobit chyby v případě, že daná transformace změní tvar tělesa v jiném směru, než jaký má tato úsečka. Pro ilustraci můžeme zadat transformaci, která nejprve otočí objekt o 45 stupňů doprava, potom provede horizontální změnu měřítka a následně objekt otočí o 45 stupňů doleva. Můžeme se přesvědčit, že zatímco tvar objektu se změní, délka úsečky zůstane konstantní.
Bylo by tedy vhodnější, aby se spočítala změna délky různě orientovaných úseček. Problém nastává v případě, že chceme spočítat výslednou pravděpodobnost. Poměr zkrácení všech úseček by se měl zprůměrovat, přičemž se musí použít geometrický průměr, ne aritmetický.
Pro co nejpřesnější výpočet můžeme jednu úsečku nahradit vektorem s pevně danou délkou, který se otáčí okolo středu. Při jedné otočce vektoru se tedy vypočítá obsah kružnice o poloměru rovném délce vektoru. Musí se tedy provést integrace, aby se zjistil obsah této kružnice:
| (1.93) |
Poté se vypočte obsah objektu, který vznikne rotací vektoru po transformaci. Obecně musí vyjít elipsa:
| (1.94) |
Výsledná pravděpodobnost se potom opět vypočte z poměru těchto dvou ploch:
| (1.95) |
Jak je z předchozích vztahů vidět, tento způsob výpočtu pravděpodobnosti je velmi komplikovaný a časově náročný. Přitom neodstraňuje základní nevýhodu této metody, tj. lineární závislost pravděpodobnosti na změně měřítka.
Pravděpodobnost jedné transformace je v tomto případě rovna:
| (1.96) |
Všechny transformace tedy mají stejnou pravděpodobnost. Obecně má tato volba za následek nerovnoměrné rozložení hustoty bodů ve výsledném fraktálu. To je důsledkem toho, že více kontrahující transformace k sobě také více přitahují generované body. Tyto body se potom více hromadí na místech, kde je aplikována daná transformace.
V tomto případě jednotlivé pravděpodobnosti zadává přímo uživatel. Program potom zajistí, aby byl součet všech pravděpodobností roven jedné a aby žádná pravděpodobnost nebyla nulová.
Při tomto způsobu zadávání pravděpodobností můžeme otestovat, jaký fraktál bude generován při různých poměrech jednotlivých pravděpodobností. Z výsledků můžeme vidět, že se tvar výsledného fraktálu nezmění. Změní se jen hustota bodů na některých místech fraktálu.
Můžeme tedy učinit závěr, že transformační matice udává tvar výsledného fraktálu a pravděpodobnost transformace udává hustotu bodů při aplikaci této transformace.
V této části jsme popsali některé možnosti výpočtu pravděpodobností jednotlivých transformací. Je nutné připomenout, že zatímco transformační matice je přesně zadaná a odpovídá tomu, co zadal uživatel, výpočet pravděpodobnosti není jednoznačný.
První nejednoznačnost vyplývá z vlastního výpočtu pravděpodobnosti. V tomto případě je nejpřesnější metoda, která porovná plochu základního objektu a transformovaného objektu. Tato metoda počítá přímo ze zadaných dat základního objektu (souřadnice vrcholů) a ne pouze z transformačních matic.
Druhá nejednoznačnost nastane, není-li základní objekt zcela přesně pokryt transformovanými objekty. V tom případě nebude po základním výpočtu součet všech pravděpodobností roven jedné. Program samozřejmě provede takovou úpravu, aby byl součet roven jedné, jinak by nebylo možné provést generování IFS koláže.
Problémem však je, jak upravit jednotlivé pravděpodobnosti, aby byl součet jednotkový. Můžeme část zbývající do jedné rozdělit rovnoměrně mezi všechny pravděpodobnosti, nebo můžeme rozdělení provést tak, že zohledníme hodnotu jednotlivých pravděpodobností. Žádná z těchto možností není přesná, neboť u špatně provedeného pokrytí základního objektu neexistuje přesný vztah mezi transformací a její pravděpodobností. Tento vztah platí pouze u přesného pokrytí, tj. transformované objekty úplně pokryjí základní objekt, přičemž se tyto objekty navzájem nepřekrývají.
Všechny tyto skutečnosti se musí zohlednit při porovnávání pravděpodobností, které vznikly výpočtem podle různých metod.
Algoritmus výpočtu IFS kódu je v tomto programu velmi jednoduchý, protože jsou v programu přímo uloženy jednotlivé transformace. Není tedy nutno pro každé zobrazení IFS koláže počítat koeficienty transformační matice. Algoritmus tedy může vypadat následovně:
Výpočet sumy pravděpodobností je nutný, aby se zaručilo, že součet všech pravděpodobností v IFS bude roven jedné. To se provede tak, že se spočítá suma všech vypočítaných pravděpodobností. Obecně může vyjít libovolné kladné reálné číslo. Touto sumou potom podělíme jednotlivé pravděpodobnosti. Po této operaci je nová suma všech pravděpodobností rovna jedné, tak jak to vyžaduje vykreslovací algoritmus i definice IFS.
Zajímavý je bod 3, který zjišťuje, zda je daná transformace kontrakcí. Transformace mohou být, jak již bylo řečeno, obecně trojího druhu:
Kontrahující transformace je taková transformace, která po provedení operace na úsečku zkrátí její délku. Úsečku si můžeme představit jako dva body, jejichž vzdálenost měříme. Po provedení transformace se musí tato vzdálenost zmenšit.
Extrahující transformace naopak úsečku natahuje, to znamená, že se body od sebe vzdalují. Symetrie je na hranici mezi kontrakcí a extrakcí, zachovává tedy délku úsečky i vzdálenosti jednotlivých bodů. Mění se tedy pouze poloha těchto bodů v rovině a jejich vzájemná orientace.
Typ transformace můžeme vypočítat přímo z transformační matice M dané transformace pomocí jednoduchého vztahu:
| (1.97) |
Hodnota koeficientu udává, o jaký typ transformace se jedná:
Z definice IFS plyne, že transformace použité v IFS mohou být pouze kontrakcemi, v krajním případě symetriemi. Uživatel má možnost otestovat jím zadané transformace, do jakých kategorií patří. Lze generovat i fraktál, který obsahuje extrakci, pak už to však není IFS, protože neodpovídá definici (také nemusí jít o fraktál, protože zde může být atraktorem pouze nekonečno). Může nastat i matematická chyba v programu v důsledku počítání s příliš velkými čísly. V každém případě je však možnost práce s extrakcemi umožněna, protože jde o program určený k studijní činnosti a ne o komerční produkt chráněný proti všem špatným vstupům.
| Předchozí kapitola | Další kapitola | Obsah | Úvodní stránka | Domácí stránka |