Experiments with FrameLink FIFO
First evaluation of HAVEN performance was accomplished with FIFO buffer component that use FrameLink communication protocol. We focused on verification of a large number of very short data transactions (1-36 B). Table 1 compares the times of the whole verification runs of the non-accelerated version (NAV) to the times of runs of the accelerated version (AV) and the acceleration ratio (Acc).
| Transactions | FIFO | ||
|---|---|---|---|
| NAV [s] | AV [s] | Acc [-] | |
| 50,000 | 49 | 26 | 1.885 |
| 100,000 | 99 | 52 | 1.904 |
| 200,000 | 197 | 104 | 1.894 |
| 500,000 | 492 | 258 | 1,907 |
During the experiments, we observed that a considerable amount of time is taken by generating transactions, therefore we also measured the times of verification runs without the time of transaction generation, as this value is the same for both the accelerated and the nonaccelerated version. These results for FIFO component are given in Table 2. It can be seen from both provided tables that the acceleration ratio is proportional to the complexity of the verified component.
| Transactions | FIFO | ||
|---|---|---|---|
| NAV [s] | AV [s] | Acc [-] | |
| 50,000 | 24 | 1 | 24.000 |
| 100,000 | 49 | 2 | 24.500 |
| 200,000 | 97 | 4 | 24.250 |
| 500,000 | 242 | 8 | 30.250 |
Table 3 summarises the number of Virtex-5 slices used by the verification core of the accelerated version with the verified component (column Slices) and the total number of occupied slices of the FPGA together with NetCOPE (column Total slices). Total number of slices available (Xilinx Virtex-5 XC5VLX155T) is 24,320. Column Build time gives the time it took to generate the firmware for the FPGA. It can be observed that this time increases significantly as the total resource consuptiom approaches the capacity of the FPGA.
| Component | Slices | Total slices | Build time [s] | B-E transactions |
|---|---|---|---|---|
| FIFO | 420 (1.7 %) | 9,362 (38.5 %) | 1,473 | 3,116,000 |
The computed break-even number of transactions, which is, loosely speaking, the number of transactions for which is, loosely speaking, the number of transactions for which the acceleration starts to be beneficial, is further given in column B-E Transactions Formally, this number is defined as the number transbe such that
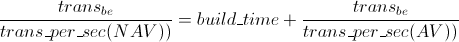
where build_time is the build time of the firmware (in seconds) and trans_per_sec(AV) and trans_per_sec(NAV) are the average number of transactions processed in a second by the accelerated and the non-accelerated version, respectively.
All experiments were performed using COMBOv2 LXT155 equipped with Xilinx Virtex-5 FPGA acceleration card, attached to a two Intel Xeon quad-core E5420@2.50 GHz processor based server with 10 GiB of RAM. As the SystemVerilog interpreter a Mentor Graphic's ModelSim SE-64 6.6a was used.